~~~~~~~~~~~~~~~~~~~~~~
Pour aller plus loin sur la Régression Logistique:
vous trouverez une liste de documents présentant plus amplement le modèle logistique en cliquant sur le lien suivant:
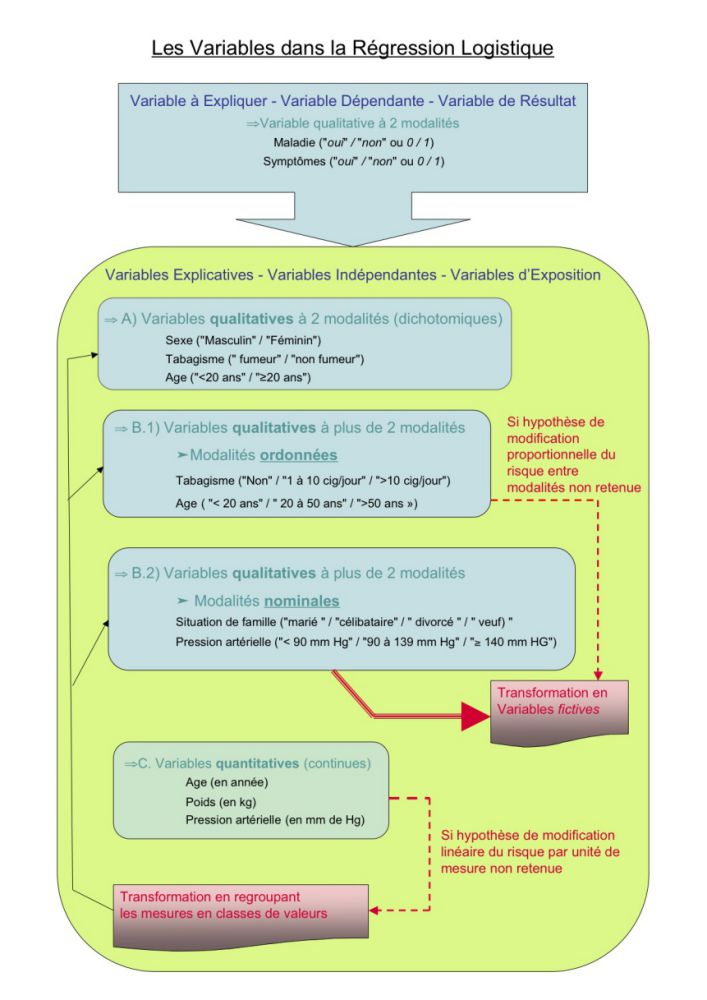
Schéma résumé des types de variables inclues dans une régression logistique
Article publié le 24 janvier 2018

. Annexe: Les types de variables explicatives dans La Régression Logistique avec Epi Info:
Quatre grands types de variables dites explicatives dans la régression logistique, peuvent être définis. Selon ce type les variables sont introduites dans le modèle telle quelle, ou elles doivent être modifiées.
Ces types sont décrits en suivant:
A) Les variables qualitatives à 2 modalités (dichotomiques).
Elles sont codées oui/non, 0/1, … comme la présence ou l'absence d'une exposition, le sexe des sujets de l'étude.
Elles n'ont pas à être modifiées.
B.1) Les variables qualitatives ordinales à plus de 2 classes
Elles sont :
soit gardées telles quelles si on fait l'hypothèse que la modification du risque est proportionnel entre les modalités;
soit, si cette hypothèse semble trop forte, on traite alors cette variable comme variable à modalité nominale, et elle doit être transformée en variables fictives.
Par exemple dans le cas du calcul de l'association entre une maladie et le tabagisme codé en non fumeur/ fumeur de moins de 10 cigarettes/jour / fumeur de plus de 10 cigarettes/jour, si le risque est supposé proportionnel, cela veut dire que le le risque de la maladie est le même entre les modalités non fumeur et fumeur de moins de 10 cig / jour, et entre fumeur de 10 cig/jour et fumeur de plus de 10 cig/jour. Un fumeur de moins de 10 cig/jour aura le même risque de maladie par rapport à un non fumeur, qu'un fumeur de plus de 10 cig/jour par rapport à un fumeur de moins de 10 cig/jour.
B.2) Les variables qualitatives nominales à plus de 2 classes
Elles doivent être transcodées (leur codage doit être modifié), sinon le modèle logistique les interprète comme des variables quantitatives si elles ont un code numérique.
On doit alors créer c-1 variables "fictives", c étant le nombre de modalité de la variable considérée, et choisir une modalité de référence.
Par exemple, pour une variable comme la situation de famille codée en célibataire/marié/divorcé/veuf (soit 4 modalités), il faudra créer 3 variables fictives.
Dans la fenêtre de la commande LOGISTIQUE d'Epi Info, le bouton "Créer Fictif" permet de créer automatiquement ces variables fictives (cf message sur la régression logistique avec une variable nominale).
C) Les variables quantitatives
Ce sont les variables comme l'âge, le poids, la pression artérielle...
Elles n'ont pas à être modifiées à prior pour être introduit dans un modèle de régression logistique.
Cependant pour les variables quantitatives ont fait alors l'hypothèse que le risque de "maladie" augmente (ou diminue) de façon linéaire par unité de mesure.
Par exemple dans le cas d'une augmentation du risque avec l'âge, on ferait l'hypothèse que ce risque augmenterait de la même façon entre 20 et 30 ans qu'entre 40 et 50 ans.
Cette hypothèse est assez forte et doit être vérifiée au préalable.
Si cette hypothèse n'est pas retenue, on peut transformer ces variables quantitatives en regroupant les mesures en classes de valeur (par exemple des classes d'âge), et traiter ensuite cette nouvelle variable comme une variable qualitative à modalités ordonnées ou nominales, ou comme une variable dichotomique si l'on ne choisit que 2 classes de valeur.
Par exemple, la pression artérielle systolique peut être classées en 3 groupes de valeurs qui sont ordonnés, mais une tension inférieure à 90 mm Hg définit une hypotension, et une valeur supérieure à 140 mm Hg définit une hypertension. Donc on peut être amené à traiter les mesures de tension artérielle comme une variable à 3 modalités non ordonnées, car c'est la modalité "du milieu" qui définit une tension dans les normes, et les classes de valeurs extrêmes, hypotension et hypertension, qui augmenteront à priori le risque de maladie.
Sommaire
. Annexe: les types de variables explicatives

La Régression Logistique dans Epi Info 7 (5/5)

