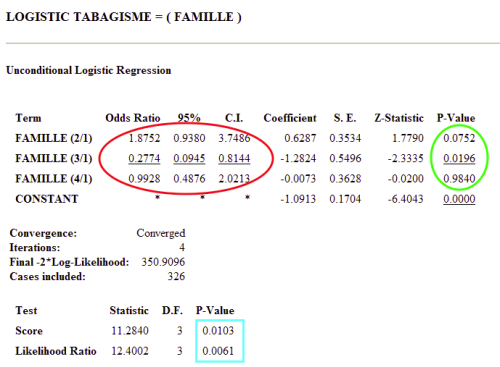
Cette fois l'Odds Ratio de la modalité DIVORCE (codée 3) est calculé par rapport à la modalité de référence MARIE (codée 1), et est égale à 0,277.
La valeur est proche de celle de l'OR par rapport à la modalité CELIBATAIRE, car dans les deux groupes célibataire et marié, la prévalence du tabagisme est proche (autour de 25 %).
On remarque enfin que les p du modèle global (encadré en bleu) sont les mêmes que précédemment, car la variable situation de famille est la même, seul le groupe de référence change.
En relançant la régression logistique avec le nouveau codage (dans la table de donnée, la situation de famille est codée numériquement dans la variable FAMILLE), on obtient les résultats suivant:
~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~
Pour choisir une autre modalité de référence, il faut, par exemple changer le codage de la variable nominale, en adoptant un codage numérique (avec les commandes DEFINIR et TRANSCODER du module d'analyse d'Epi Info), et en assignant à notre modalité de référence le code le plus bas.
En reprenant notre variable Situation de Famille, si on veut que la modalité MARIE devienne la modalité de référence (car on veut connaitre la probabilité d'être fumeur dans les autres situations de famile par rapport à celle des personnes mariées), on peut changer le codage des 4 modalités comme suit, en assignant des valeurs numériques:
MARIE -> 1
UNION LIBRE -> 2
DIVORCE -> 3
CELIBATAIRE -> 4
!!! Attention !!!
Si la modalité de référence est différente, on trouvera bien sûr, des valeurs d'Odds Ratio différentes pour les autres modalités.
Ici c'est Epi Info qui a choisi automatiquement cette modalité de référence qui est donc relative.
2.2 Remarque sur le calcul de l'Odds Ratio dans le cas d'une variable nominale:
La formule de l'Odds Ratio pour le tabagisme des sujets divorcés (au numérateur) par rapport aux sujets célibataires, pris comme référence, (au dénominateur) donne:
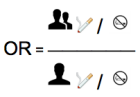
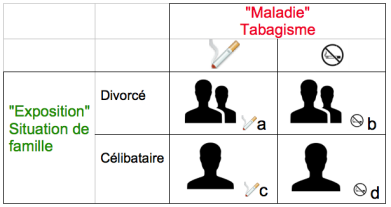
Pour le calcul de l'OR correspondant à la modalité suivante, DIVORCE, si on reprend la notation du tableau 2X2 donné dans l'introduction, on a :
la "maladie" est ici le tabagisme,
et le facteur d'exposition est ici la situation de famille, avec la modalité de référence CELIBATAIRE, et celle dont on va calculer l'OR, DIVORCE
En remplaçant par les valeurs numériques, on obtient:
* au numérateur de l'OR correspond le rapport du nombre de sujets fumeurs sur celui des non fumeurs parmi les sujets divorcés (a/b) soit: 4 / 43 = 0,093
* au dénominateur de l'OR correspond le rapport du nombre de sujets fumeurs sur celui des non fumeurs parmi les sujets célibataires (modalité de référence) soit: 13 / 39 = 0,333
L'Odds Ratio correspond au rapport entre ces deux rapports, soit: 0,093 / 0,333 = 0,279
On retrouve bien la valeur calculée par le modèle logistique pour la modalité divorcé, par rapport à la modalité de référence célibataire.
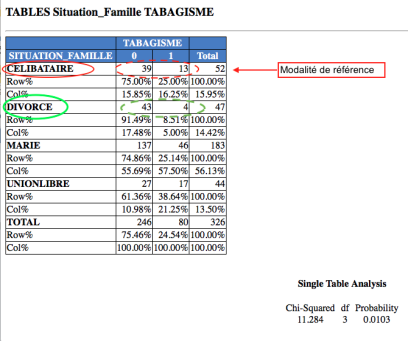
En reprenant l'exemple précédent, à partir du résultat du croisement des variables TABAGISME et SITUATION_FAMILLE, obtenu avec la commande TABLES, on peut retrouver les valeurs des OR.
La modalité de la variable SITUATION_FAMILLE qui apparait en premier (c'est la première d'après le classement alphabétique) est celle prise comme référence pour Epi Info, c'est donc CELIBATAIRE.
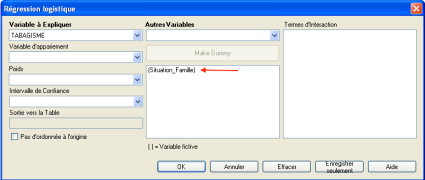
La variable "Situation_Famille" apparait alors entre parenthèses dans la liste Autres Variables.
Remarque:
La variable étant de type numérique Epi Info aurait de toute façon automatiquement créé des variables fictives.
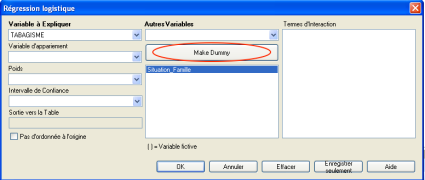
☞ Toujours dans la boîte de dialogue REGRESSION LOGISTIQUE, pour indiquer à Epi Info la création de variables fictives, on sélectionne la variable "Situation_Famille" en cliquant une fois dessus, puis on clique sur le bouton "Créer Fictif" juste au dessus.
Note au sujet des données:
Les données de cet exemple sont fictives, tirées de la table de données "Smoke" du projet contenant des exemple de données en anglais "Sample.prj" inclus dans le logiciel Epi Info.
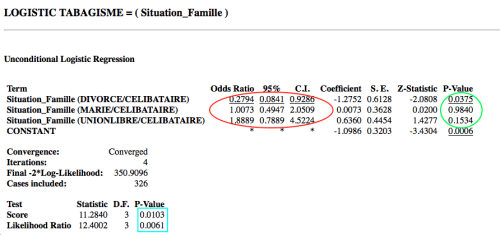
Dans la fenêtre résultat, on lit les valeurs des Odds Ratio (entourés en rouge) entre le statut tabisme et les modalités de la situation de famille, la modalité CELIBATAURE étant prise comme modalité de référence, ainsi que les valeurs de l'intervalle de confiance à 95 %, et enfin les valeurs p de significativité du test d'association (entourées en vert).
Ainis:
l'OR du tabagisme des sujets divorcés par rapport aux sujets divorcés est de 0,28, et cet OR est significativement différent de 1 car le p < 0,04;
l'OR du tabagisme des sujets mariés par rapport aux sujets divorcés est de 1,01, et cet OR n'est pas significativement différent de 1 car le p > 0,05, et l'intervalle de confiance à 95 % inclut 1;
l'OR du tabagisme des sujets en union libre par rapport aux sujets divorcés est de 1,89, et cet OR n'est pas significativement différent de 1 car le p > 0,05, et l'intervalle de confiance à 95 % inclut 1.
On peut donc dire que, dans notre échantillon d'étude, par rapport aux sujets célibataires (modalité de référence):
les personnes divorcées ont une probabilité plus faible de fumer (l'OR est inférieur à un),
les personnes mariées ou celles en union libre ne diffèrent pas pour le statut tabagique.
Les valeurs p qui apparaissent en bas (encadrées en bleue, p est inférieur à 0,02) correspondent au degrés de signification de la variable Situation de Famile dans son ensemble.
Même si les OR de certaines modalités de la variable ne sont pas significativement différentes de 1, on dit que le facteur Situation de famille est statistiquement lié au tabagisme.
Les résultats de la régression logistique apparaissent alors dans la fenêtre de sortie:
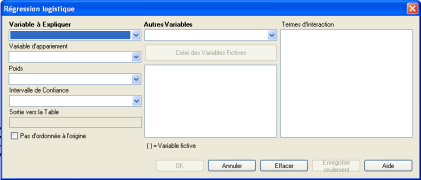
☞ Dans la fenêtre de la Régression Logistique qui apparaît, il faut d'abord sélectionner la variable à expliquer dans le champ en haut à gauche "Variable à Expliquer", ici la variable "TABAGISME", puis sélectionner les variables explicatives, dans le champ nommé "Autres Variables" au milieu en haut, ici les variable "Situation_Famille".
A partir du module d'Analyse des Données Classique, on doit d'abord lire la table de données de notre exemple (projet "Tabagisme.mdb", table "Tabagisme")
Pour illustrer le calcul d'un modèle logistique avec une variable explicative qualitative nominale, prenons l'exemple d'une enquête sur la tabagisme chez des adultes. Le questionnaire recueille le statut tabagique des sujets (êtes-vous fumeur ?) avec des informations sociodémographiques (sexe, âge, situation familiale).
On veut, à partir des données de l'enquête, estimer l'associations entre le statut tabagique des personnes et leur situation de famille.
Le statut tabagique (fumeur/ non fumeur) est notre variable de résultat, notre variable à expliquer.
La situation familiale (marié / union libre / divorcé / célibataire) est notre variable explicative (qualitative nominale à 4 modalités) ou variable d'exposition.
On a donc:
2.1 Exemple de calcul d'une régression logistique avec une variable explicative nominale
☞ Pour calculer le modèle logistique, on utilise la commande REGRESSION LOGISTIQUE qui se trouve dans le groupe des commandes "Statistiques Avancées".
Facteur de Risque
(variable explicative, indépendante)
Situation Familiale
Maladie ou Symptômes
(variable à expliquer, dépendante):
Statut Tabagique


Article publié le 8 février 2018

3. La Régression Logistique avec une variable explicative nominale dans Epi Info 7:
Après avoir abordé la régression logistique simple avec la commande LOGISTIQUE d'Epi Info 7, puis la régression logistique multiple, cet article traite du cas particulier de la prise en compte dans le modèle d'une variable explicative qualitative de type nominal (cf cas B2 du récapitulatif des types de variables).
En effet, ce type de variable à plus de 2 modalités doit être transformé en créant des variables dites "fictives".
Epi Info crée automatiquement ces variables fictives à partir d'une variable qualitative nominale si elle est de type texte, sinon, si elle est de type numérique (avec un code numérique), il faut indiquer à Epi Info la création de ces variables fictives en utilisant le bouton "Créer des Variables Fictives" (ou "Make Dummy" en anglais) dans la fenêtre de la commande LOGISTIQUE.
Les Odds Ratio qui seront alors calculés par le modèle logistique seront les OR d'une modalité donnée de la variable qualitative originale par rapport à une modalité de référence choisie par Epi Info.
Cette modalité de référence :
•en cas de code numérique, la valeur minimale;
•en cas de texte, le nom de la modalité classée alphabétiquement en premier.
Sommaire
3. La Régression Logistique avec une variable nominale.

La Régression Logistique dans Epi Info 7 (4/5)

